
新Linux入門|パイプを理解しよう!コマンドをつなげて処理を自動化
Linuxを使いこなす上で欠かせないのが「パイプ(|)」です。
パイプを使うと、あるコマンドの出力結果を次のコマンドの入力として受け渡すことができ、複数の処理を一気に自動化できます。
たとえば、「ファイル一覧を取得して、その中から特定の拡張子を持つものだけを表示する」などの操作を、
一行でスマートに実現できます。
🔗 パイプとは?
パイプ(pipe)は、コマンド同士をつなぐための仕組みです。
1つ目のコマンドの標準出力(stdout)を、2つ目のコマンドの標準入力(stdin)として渡します。
| 項目 | 説明 |
|---|---|
| 記号 | | |
| 役割 | 1つ目のコマンドの出力を2つ目のコマンドの入力に渡す。 |
| 例 | ls | less |
| メリット | コマンドを組み合わせて、効率的な自動処理ができる。 |
💬 ポイント
リダイレクト(>)が「ファイルへ出力」するのに対して、パイプは「次のコマンドへ出力」します。
つまり、ファイルを経由せずにデータを直接受け渡すことができるのです。
🧭 パイプの基本構文
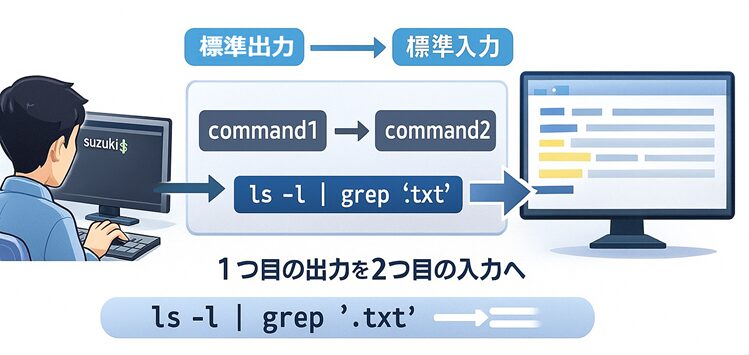
パイプの基本的な書式はとてもシンプルです。
コマンド1 | コマンド2📘 例
[suzuki@AlmaLinux ~]$ command1 | command2これは「command1 の出力を command2 に渡す」という意味になります。
パイプは何段でもつなげることができ、command1 | command2 | command3 のように連続して使うことも可能です。
⚙️ パイプの動作イメージ
| 項目 | 説明 |
|---|---|
| コマンド1 | データを出力する(例:ls、cat など) |
| パイプ( | ) | | |
| コマンド2 | コマンド1の出力を入力として受け取り、さらに処理する(例:grep、sort など) |
💬 ポイント
パイプはメモリ上で直接データを渡すため、ファイルに保存するよりも高速で効率的です。
また、パイプラインを作ることで、「出力→加工→整形→絞り込み」といった流れを一気に処理できます。
🧩 パイプの利点
| 利点 | 説明 |
|---|---|
| コマンドを組み合わせて使える | 複数のシンプルなコマンドを組み合わせて、複雑な処理を一行で実現できる。 |
| リダイレクトより柔軟 | ファイルに書き出すことなく、次のコマンドに直接データを渡せる。 |
| メモリ効率が良い | ファイルを作成せずストリーム形式でデータを流すため、高速で無駄がない。 |
| シェルスクリプトで強力 | データ加工や抽出を自動化するシェルスクリプトで頻繁に使われる。 |
💬 つまり、パイプはLinuxにおける「コマンド連携の接着剤」と言えます。
1つ1つの小さなコマンドをつなげることで、まるでパズルのように処理を組み立てられるのです。
🧾 パイプの使用例と解説
➀ ls と grep の組み合わせ
特定の拡張子を持つファイルだけを表示します。
[suzuki@AlmaLinux ~]$ ls -l | grep ".txt"
-rw-r--r-- 1 suzuki suzuki 1120 10月 28 06:12 notes.txt
-rw-r--r-- 1 suzuki suzuki 532 10月 28 06:15 data.txt💬 解説
- ls -l … 現在のディレクトリ内のファイルを一覧表示
- grep ".txt" … 「.txt」を含む行だけを抽出
結果として、.txt ファイルのみをすばやく確認できます。
② cat と less の組み合わせ
長いファイルをページ単位で閲覧します。
[suzuki@AlmaLinux ~]$ cat longfile.txt | less💬 解説
cat がファイル内容を出力し、less がそれを受け取ってページャ形式で表示します。
ファイルが長くても、スクロールしながら快適に閲覧できます。
③ sort と uniq の組み合わせ
重複する行を取り除いて一意の行を抽出します。
[suzuki@AlmaLinux ~]$ sort data.txt | uniq
apple
banana
orange💬 解説
sort でデータを並べ替え、uniq が重複行を削除します。
これにより、ファイル内の重複データを簡単に整理できます。
➃ パイプを複数つなげる例
複数のコマンドを組み合わせて高度な処理を実行します。
[suzuki@AlmaLinux ~]$ cat access.log | grep "error" | sort | uniq -c | sort -nr | head -5💬 解説
- cat がログを読み込み
- grep が「error」を含む行を抽出
- sort で並び替え
- uniq -c で重複カウント
- sort -nr で回数順にソート
- head -5 で上位5件を表示
💬 このように、パイプを連ねることで、リアルタイムで分析的な処理が可能になります。
⚠️ パイプを使うときの注意点
| 注意点 | 説明 |
|---|---|
| 長すぎるパイプラインは避ける | 可読性を損ねるため、3〜4段階程度に整理するのが理想 |
| エラー出力は流れに含まれない | パイプは標準出力(1)のみを渡すため、標準エラー(2)は別に処理が必要 |
| コマンドの実行順序に注意 | 前のコマンドが成功して初めて次のコマンドにデータが渡る。 |
💬 この図を用いると、「出力→入力→結果」という流れが直感的に理解できます。
コマンド間でデータが流れていく様子を視覚的に覚えると、パイプの仕組みがスッと頭に入ります。
✅ まとめ
パイプは、Linuxのコマンド操作をより強力でスマートにする仕組みです。
ファイルの検索・集計・整形など、複雑な処理も一行のコマンドで自動化できます。
| 操作内容 | コマンド例 | 説明 |
|---|---|---|
| ファイル一覧から特定の拡張子を検索 | ls -l | grep ".txt" | .txtファイルを抽出 |
| 長いファイルをページ表示 | cat filename.txt | less | ページャで閲覧 |
| 重複行を削除 | sort data.txt | uniq | 一意な行を抽出 |
| ログのエラー解析 | cat access.log | grep "error" | sort | uniq -c | 出現回数を集計 |
💬 ポイント
- パイプはコマンド同士の“橋渡しをするツール。
- リダイレクトと違い、リアルタイムでデータを受け渡せる。
- 慣れると「ls」「grep」「sort」「uniq」「wc」などを自由に組み合わせて、自分だけのワンライナーを作れるようになります。
パイプを使いこなせば、あなたのLinux操作がぐっとスピーディーで効率的になります!