
新Linux入門|正規表現を理解しよう!文字列パターンとメタキャラクタの基本
Linuxでテキストを扱う際、「特定の文字列を探したい」「条件に合う行だけ抽出したい」といった場面はよくあります。
そんなときに大活躍するのが 正規表現(Regular Expression) です。
正規表現とは、文字列のパターン(規則)を表現するための特別な記法のことで、
grepやsed、awkなどのコマンドで頻繁に使われます。
ファイルの検索、ログの分析、テキスト置換など、システム管理者にとって欠かせない知識です。
ここでは、正規表現の基本的な考え方と、よく使われるメタキャラクタ(特殊記号)についてわかりやすく解説します。
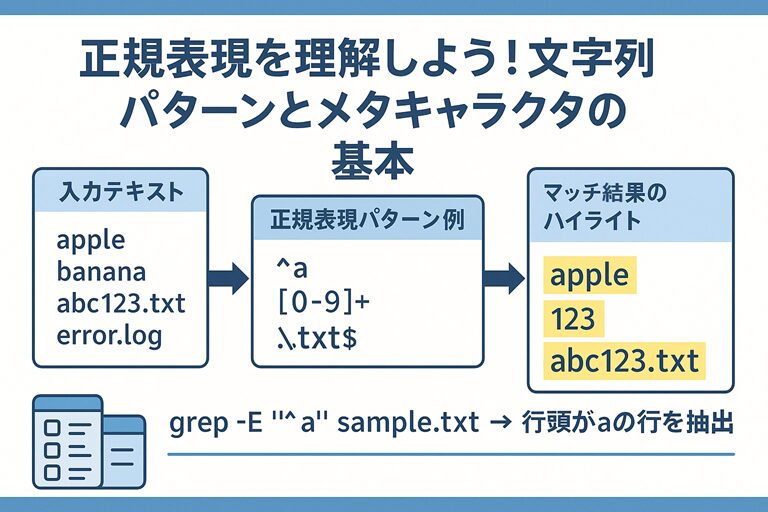
🧩 正規表現とは?
正規表現(Regular Expression)は、
「あるルールに合った文字列」を柔軟に検索・抽出するためのパターン表現です。
例えば、次のような用途で使われます。
| 目的 | 例 |
|---|---|
| 特定の単語を含む行を抽出したい | grep "error" logfile.txt |
| 数字で始まる行を探したい | grep "^[0-9]" data.txt |
| 拡張子が .txt のファイル名を探したい | grep "\.txt$" filelist.txt |
💬 正規表現を理解しておくと、grepコマンド一つで強力な検索が可能になります。
🔣 正規表現の主なメタキャラクタ
正規表現には、特別な意味を持つ文字(メタキャラクタ)がいくつかあります。
これらを組み合わせることで、複雑なパターンを表現できます。
| メタキャラクタ | 説明 |
|---|---|
| . | 任意の1文字にマッチする。 |
| * | 直前のパターンが0回以上繰り返すものにマッチ。 |
| + | 直前のパターンが1回以上繰り返すものにマッチ(拡張正規表現)。 |
| ? | 直前のパターンが0回または1回現れるものにマッチ(拡張正規表現)。 |
| ^ | 行の先頭にマッチする。 |
| $ | 行の末尾にマッチする。 |
| [] | 角括弧内のいずれか1文字にマッチする。例:[abc] は a, b, c のいずれか。 |
| () | グループ化を行う。繰り返しや参照に使うことができる。 |
| \ | エスケープ文字。特殊文字を通常の文字として扱う。 |
💡 + と ? は 拡張正規表現 なので、grep で使う際は -E オプション を付ける必要があります。
(例:grep -E "a+b")
💡 正規表現の具体例
| パターン | マッチする文字列の例 | 説明 |
|---|---|---|
| ab* | a, ab, abb, abbb... | bが0回以上繰り返す。 |
| a+b | ab, aab, aaab... | aが1回以上繰り返す(拡張)。 |
| a?b | ab, b | aが0回または1回のときにbにマッチ(拡張)。 |
| .* | 任意の文字が0文字以上続く。 | |
| ^start | 行頭がstartで始まる。 | |
| end$ | 行末がendで終わる。 | |
| [aeiou] | 母音のいずれか(a, e, i, o, u)。 | |
| (abc)+ | abcが1回以上繰り返す。 | |
| [A-Z] | AからZまでの大文字アルファベット。 | |
| [0-9][0-9] | 2桁の数字。 | |
| .txt$ | 拡張子が.txtで終わる文字列。 |
💬 たとえば grep "^[A-Z]" とすれば、行の先頭が大文字で始まる行を簡単に抽出できます。
🧪 grepコマンドでの使用例
grep は正規表現を利用できる代表的なコマンドです。
① ファイル内で「error」を含む行を検索
[suzuki@AlmaLinux ~]$sudo grep "error" /var/log/messages
Oct 27 10:35:12 AlmaLinux systemd[1]: error: failed to start service.② 拡張正規表現で「a」が1回以上続く行を検索
[suzuki@AlmaLinux ~]$ grep -E "a+" sample.txt
aaaaa
banana③ 「.txt」で終わる行を検索
[suzuki@AlmaLinux ~]$ grep "\.txt$" filelist.txt
report.txt
memo.txt💬 \. はドットをそのまま「.」として扱うためにエスケープしています。
⚙️ シェルのメタキャラクタとの違い
正規表現とよく混同されるのが、シェルのワイルドカード(メタキャラクタ)です。
実際には用途も挙動も異なります。
| 区別 | シェルのメタキャラクタ | 正規表現 |
|---|---|---|
| 使用場所 | ファイル名展開、コマンドライン操作 | grep, sed, awk, vimなど |
| * の意味 | 任意の文字列(0文字以上) | 直前のパターンの0回以上繰り返し |
| ? の意味 | 任意の1文字 | 直前のパターンの0回または1回(拡張) |
| [ ] | 文字セットを表す(同じ) | 同じ意味で使用される |
💬 たとえばシェルの ls *.txt は「.txtで終わるファイル名」を探しますが、
正規表現の \.txt$ は「行末が .txt で終わる文字列」を探す違いがあります。
✅ まとめ
- 正規表現は、文字列のパターンを表す強力な仕組み。
- grepやsed、awkなど多くのLinuxツールで使用可能。
- メタキャラクタを組み合わせることで、柔軟かつ強力な文字列検索ができる。
- シェルのワイルドカードとは意味が異なるため、混同しないよう注意。
💬 正規表現をマスターすれば、ログ解析やテキスト処理がグッと効率的になります。
次にgrepコマンドなどで実際にパターンマッチングを体験してみましょう!